
Over the course of the past year, Documented published various stories around the impact of TikTok on migrants who made the journey to New York City based on information they had received on the platform. As a nonprofit newsroom dedicated to reporting stories for immigrant communities in New York, the reporters wanted to take a closer look at this source of information.
Investigating mis- and disinformation in various languages presents a litany of issues: people who spread false information tend to delete accounts, requiring journalists to archive accounts before they are deactivated. Much of the content that we need to look into is in audiovisual formats, making it very difficult to run simple analyses around topics that are mentioned. When trying to understand this content we also often face a huge volume of it, making any manual approach to understanding this information particularly difficult.
In the course of several months of working with community correspondents from various backgrounds, Documented developed technical and methodological approaches to managing misinformation reporting projects about TikTok.

In this post, we’re hoping to share some of them with the global journalism community, in hopes that they may be useful to others curious about this topic.
Archiving content
Mis- and disinformation campaigns tend to spring up spontaneously and then disappear as quickly as they arise. Hence, misinformation investigations often entail identifying accounts of interest and then archiving them.
Identifying accounts of interest is usually an informed editorial decision. In our case, we spoke to migrants and worked with some to better understand their TikTok consumption and found that many migrants would receive a lot of misleading information around the U.S. immigration system online. Experts then helped us identify common issues (such as predatory scammers) and gave us methods on how to find accounts, like searching for specific terms.
Also Read: TikTok Videos Spread Misinformation to New Migrant Community in New York City
Once we had a handful of accounts we wanted to examine further, we opened their profiles on a web browser, scrolled through the page until no more videos were loaded and downloaded the HTML page. We wrote a Python scraper to then extract each account’s video urls.
Using the yt-dlp, we then downloaded each video, its meta-data and archived them on a local drive (special thanks to Caitlin Gilbert at the Washington Post and Bellingcat for pointing us to that library).
Autotranscription
Working with videos can be tough, since going through them one-by-one could take a long time. To help cut down some of the work and also give us an approximate understanding of the work we’re looking at, we decided to auto-transcribe the videos we had downloaded using the open-source version of Whisper. This transcription speech recognition model, published by Open AI, is available in various languages. The performance of the model varied from language to language: We tested the library in two languages, Vietnamese and Spanish, and found the Vietnamese transcription to be unusable. While the Spanish version had some issues, it had enough accuracy for us to proceed.
How well machine learning models like Whisper (which is a specific type of machine learning model called a transformer) work is fully dependent on the data that each model was trained on and on which languages may be prioritized.
Also Read: Second-Generation Americans: What to Do When Loved Ones Are Sharing Misinformation
A new study from the Data Provenance Initiative, which is composed of more than 50 researchers from the tech industry and universities, found that more than 90% of the data sets used to train AI came from Europe and North America, MIT Tech Review reported. Less than 4% came from Africa.
Using machine learning models and other technologies largely grouped under the term artificial intelligence, or AI, comes with a big caveat: the work done with these models might not always be 100 percent accurate.
When journalists Karen Hao, Gabriel Geiger and I worked with the Pulitzer Center on a series of workshops on AI, we started thinking about just how useful machine learning and its very popular subcategory of generative AI might be in the realm of journalism. We came up with a rubric that might help journalists think about how AI might be useful, given generative AI’s propensity to hallucinate and other machine learning models’ potential for inaccuracies.
Also Read: How to Spot Misinformation
Below is a graph that depicts our thinking: It might be ‘safe’ to use AI for your reporting if the results of a task done with AI do not need to be highly accurate and do not end up getting published. For instance, you might be able to use generative AI or other machine learning to categorize a massive trove of documents in order to pare it down to a subset that you want to inspect further. Your categorizations may not be 100% accurate, meaning you might miss a document here and there that you’re interested in, but it’s good enough to help you decide whether to delve deeper into a few of them for your investigation.
On the flipside, you should not use generative AI to do a task that needs to be accurate and will end up being published. For instance, it’s not advisable to write entire articles using generative AI and publish them, since a lot of large language models are known to ‘hallucinate,’ meaning they make up false information.
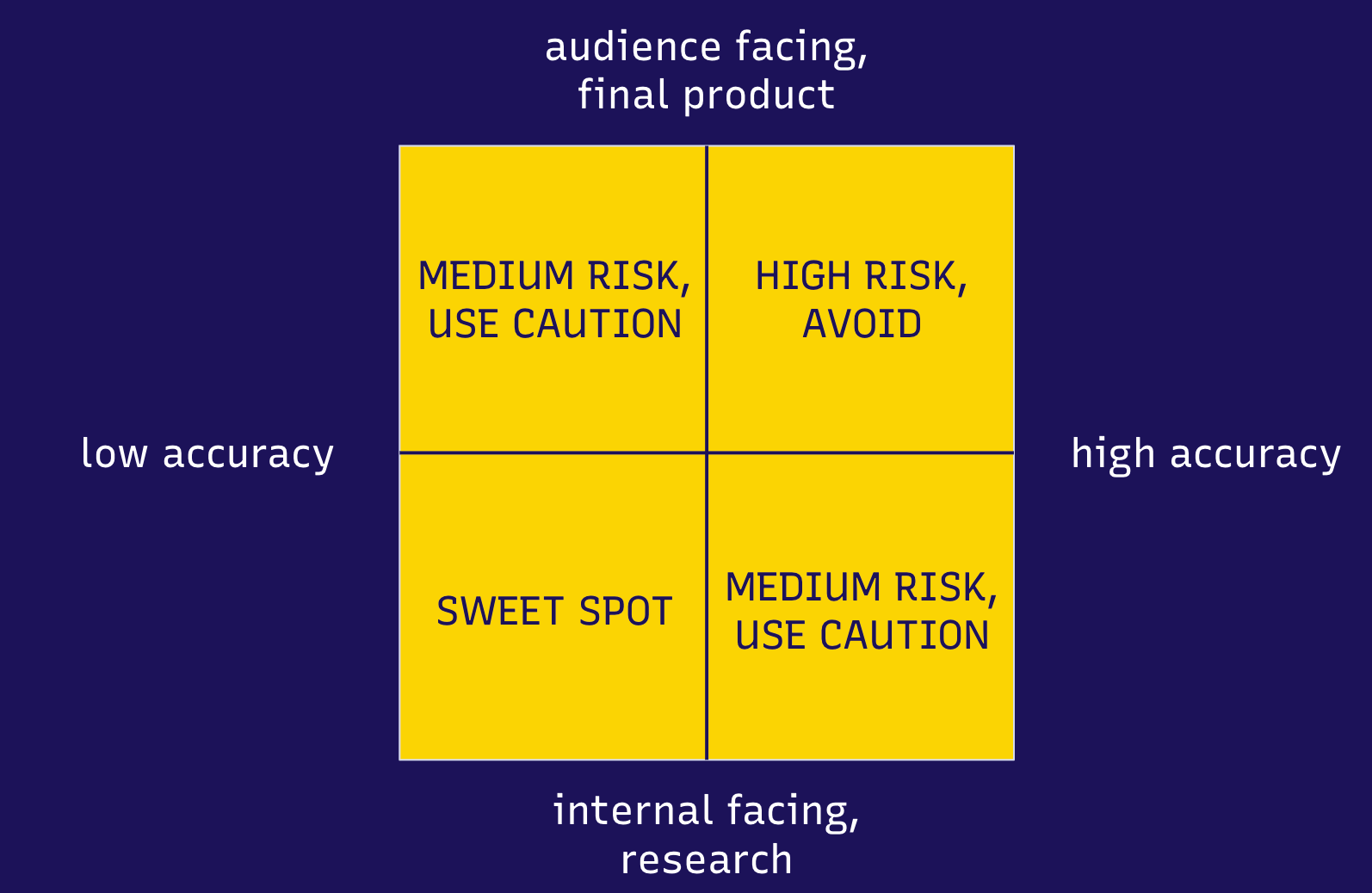
Using Whisper in this case made sense: While the transcripts were not entirely accurate, they were helpful for us to understand the gist of most videos and helped us identify videos we wanted to look at further. And since the results of this work were not for publication we felt safe in using this form of machine learning for our work.
Cutting down on the volume of content
The transcriptions also helped us find a better way to analyze the content using two other machine learning processes: natural language processing and topic modeling.
Natural language processing (NLP) is a type of machine learning that allows developers to turn large amounts of text into data so we can analyze it. You can use NLP to create simple analyses such as lists of words and how often they occur in any given text. Big technology companies like Google use it to produce word prediction, like the kind that is used in predictive search.
Topic modeling builds on top of NLP: it’s a kind of unsupervised machine learning that will look at words and try to cluster words together that seem to statistically occur close to one another. This proximity or connection between words might indicate themes that are related to one another and can be interpreted by researchers.

Thanks to our transcription we were able to do some basic topic modeling with our work which helped us identify themes we could try to look into further by looking at more videos related to those themes (like religion and CBP One, an app that migrants have to use to enter the U.S.).
Last but not least, it can also be helpful to devise a methodology to look at and describe specific videos or to narrow down a smaller pool of videos for review. Sometimes it can be helpful to describe videos that received the most views in detail to your audience. When working with an unwieldy amount of videos like tens of thousands of videos, it might also be good to take a closer look at a random sample of 1,000 videos as a representation of what an account might contain.

When writing about misinformation, it can be powerful to combine the macro-level analysis of a large corpus of content and the micro-level description of individual videos that are representative of the bigger themes that have come up.
The tech
Throughout this process we developed a Python-based code pipeline consisting of the following scripts:
- Extract links of videos from a TikTok video
- Download videos onto a local drive
- Auto transcribe videos in various languages
- Do basic topic modeling with the transcripts
You can download them all here: https://github.com/lamthuyvo/tiktok-analysis-pipeline












